Создадим устройство на основе шилда Audio Hacker и платы Arduino, которое будет изменять голос в реальном времени.
Чтобы сразу понять как это работает - лучше всего посмотреть видео ниже. За проект огромное спасибо ребятам из "nootropic design".
Комплектующие
Для этого устройства нам понадобится немного деталей:
- Arduino UNO или Genuino UNO × 1
- Audio Hacker shield × 1
- Поворотный потенциометр (универсальный) × 1
Проект
Простой проект с использованием шилда Audio Hacker для плат Arduino от компании"nootropic design". Это речевой чейнджер (от англ. - замена) в реальном времени, который является усовершенствованием исходного примера, который предоставлен в библиотеке Audio Hacker.
Мы используем технику, называемую гранулярным синтезом, чтобы изменить высоту ввода. Гранулярный синтез довольно сложен, но он включает в себя разделение семпла на маленькие фрагменты, называемые «зернами».
Гранулярный синтез (англ. Granular synthesis) — последовательная генерация звуковых гранул. Каждая гранула — это ультракороткая частица звука длиной в 10—100 миллисекунд. Звук получается в результате быстрого взаимодействия частоты повторения и частотных составляющих гранул, который далее может быть отфильтрован и сформирован огибающей методами вычитающего синтеза. Гранулами часто управляет Клеточный Автомат, который производит псевдослучайные последовательности. Гранулярный синтез очень сложен в управлении и даёт совершенно неожиданные результаты.
Одним из первых реализаций гранулярного синтеза была в программе Ross Bencina AudioMulch в виде эффекта, а уже потом появилась в виде синтезатора в Reason.
Из наиболее известных программных инструментов, применяющих гранулярный синтез, можно назвать Аbsynth, а из эффектов — Glitch. В аппаратном решении гранулярный синтез можно встретить в рабочей станции Kyma, а также в приборах обработки звука Eventide.
Теория гранулярного синтеза была разработана Дэннисом Габором.
При воспроизведении семпла, если мы хотим увеличить высоту тона, мы воспроизводим "зерно" с более высокой скоростью, но мы воспроизводим его снова и снова до тех пор, пока это не займет столько же времени, сколько и "зерно", воспроизводимое на исходной скорости. Аналогично, чтобы снизить высоту, мы воспроизводим каждое "зерно" с более медленной скоростью, но переходим к следующему "зерну раньше", чтобы общая длительность сэмпла была одинаковой.
Этот речевой чейнджер в реальном времени только снижает высоту звука. Повышение высоты звука потребует задержки для записи чего-либо и более быстрого воспроизведения фрагментов. Понижение высоты звука достигается записью входа и одновременным его замедленным воспроизведением. То есть «воспроизводящая головка» движется медленнее, чем «записывающая головка». Иногда воспроизводящая головка должна пропускать некоторые входные данные и догонять записывающую головку. Таким образом, воспроизведение занимает столько же времени как запись, что создает ощущение реального времени.
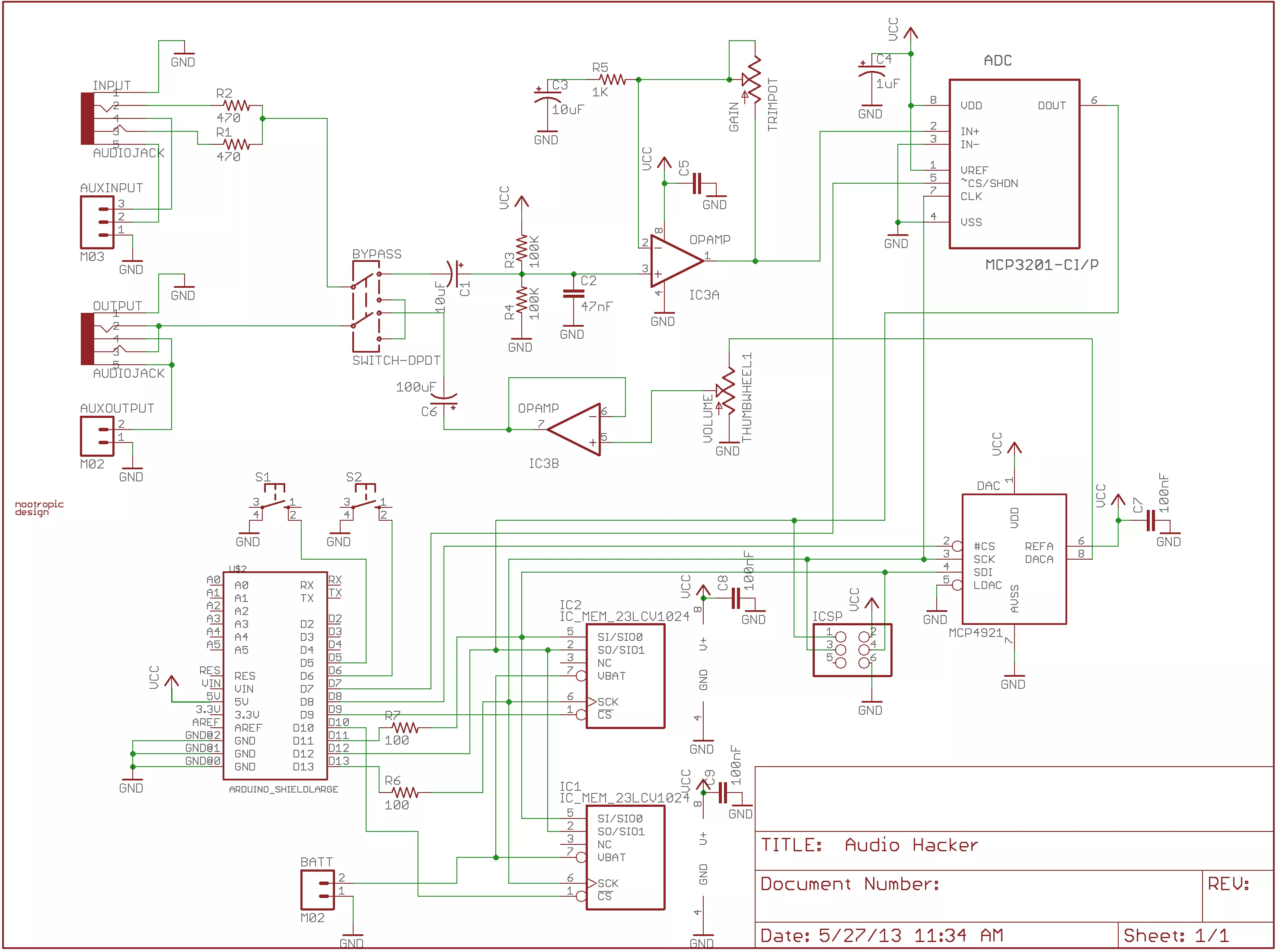
Схема устройства
Схема нашего устройства представлена на изображении ниже. Нажмите для увеличения.
Код проекта
Примеры и основной код устройства в архиве ниже, а также на GitHub странице автора. Вы можете загрузить библиотеку в IDE Arduino с помощью:
File -> Examples -> Audio Hacker -> RealtimeVoiceChanger
Скачать архив:
На этом всё. Надеемся, что вы будете использовать это устройство только в законных целях.
4 октября 2020 в 04:07
Интересно, а возможно ли приобрести Audio Hacker shield не у производителя, на алишке например? Про саму ардуинку и переключатель, понятно, на алике этого добра полно, а вот остальное…
15 октября 2021 в 19:33
а вы находили производителя?
23 сентября 2023 в 21:29
А зачем? Тут схема есть, код есть. Остаётся только самому собрать. Или вам лень?